上下文工程是什么:2026 比提示词工程更重要的新技能(含 Prompt Caching 省钱实测)
上下文工程(context engineering)是什么?为什么 2026 它比提示词工程更重要?我用真实项目讲清上下文压缩、分层检索、Prompt Caching 怎么用,并给出实测省 token/省钱数据(实测示意)。附 DeepSeek 缓存对比与 4 条 FAQ。
上下文工程是什么?一句话 TL;DR
上下文工程(context engineering)是什么? 它是"在大模型每次推理时,精心筛选并维护那一组最优 token(信息)"的工程实践——不只写好提示词,而是管理喂给模型的全部上下文:系统指令、工具定义、检索到的资料、历史对话、长期记忆。一句话 TL;DR:提示词工程教你"怎么说",上下文工程决定"模型手里有什么牌"。2026 年,后者才是拉开差距的乘数。
我是 dfkai,真实在拿各种 AI 工具做项目的人。这半年我最大的体感变化,就是从"反复打磨一句 prompt",变成"反复调整丢给 Agent 的上下文配置"。这篇 context engineering 教程,我会把概念、为什么 2026 更重要、三套实战手法(上下文压缩 / 分层检索 / Prompt Caching),以及**我项目里实测 Prompt Caching 省了多少 token 和钱(实测示意)**讲清楚。
本文是我"用 AI Agent 从零做项目"系列的一篇,想看完整工程链路,建议先读支柱长文 用 AI Agent 从零做一个真实项目。
上下文工程 vs 提示词工程:到底差在哪
先把名词掰开。Anthropic 官方工程博客《Effective context engineering for AI agents》给的定义很清楚:提示词工程关注"写好和组织指令",而上下文工程是"在 LLM 推理期间,策划与维护那一组最优 token 的全套策略,包括所有可能落进上下文窗口、但不属于提示词本身的信息"(来源:Anthropic Engineering)。
中文社区把这件事讲得也很到位:Prompt Engineering 是 Context Engineering 的一个子集,前者专注写好"指令",后者专注提供最相关的"背景信息"(来源:wangjun.dev 中文指南)。
我做了一张对照表,这是我自己用下来的真实区别(自跑对比):
| 维度 | 提示词工程 | 上下文工程 |
|---|---|---|
| 优化对象 | 怎么说(措辞、结构、few-shot) | 模型能拿到什么(资料、记忆、工具) |
| 作用范围 | 主要是 system / user prompt | tools + system + memory + RAG + 历史 |
| 时机 | 写好一次,基本固定 | 每一轮推理都在重新决策 |
| 失败表现 | 模型听不懂指令 | 模型"上下文中毒/遗忘/分心" |
| 2026 定位 | 入场门槛(table stakes) | 拉开差距的乘数(multiplier) |
Anthropic 的核心原则我特别认同:目标是找到**"能最大化期望结果概率的、最小的那组高信号 token"**。不是塞得越多越好——这就引出下一节。
为什么 2026 上下文工程比提示词工程更重要
"提示词工程已死,未来属于上下文工程"是 2026 年中外社区都在刷的话题。我的理解是三个原因叠加:
1. 模型在商品化,指令的边际收益在递减。 现在的模型(Claude Opus 4.x、DeepSeek V4、GPT 系列)已经足够听话,你少写两句"请一步步思考"基本不影响结果。竞争焦点正从"模型能力"转向"情境能力"(来源:Simon Liu 2026 GenAI 趋势)。
2. "上下文腐烂(context rot)"是真实存在的。 Anthropic 指出:随着上下文窗口 token 增多,模型准确率会下降——这是 Transformer 注意力机制的架构性限制。我自己做长任务 Agent 时深有体会:对话拉到很长之后,它开始"忘事"、重复犯错。所以堆满 200K 窗口绝不是解法。
3. Agent 时代上下文是动态的,不是写死的。 一个真正干活的 Agent,每一步都在决定"这一轮该让模型看到哪些文件、哪些历史决策、哪条文档还有效"。这正是为什么我把自己定位成"上下文的架构师"而不是"提示词写手"。这套思路在 Claude Code 子代理与 Agent 团队 那篇里也有体现——多代理本质就是给每个子任务一个干净的上下文窗口。
实战手法一:上下文压缩与结构化笔记
第一套手法解决"长任务越跑越笨"的问题。Anthropic 给的两个方法我都在用:
- 上下文压缩(compaction): 接近窗口上限时,把历史对话总结一遍,保留架构决策和关键细节,丢掉冗余的工具输出,然后用压缩后的上下文重新开始。
- 结构化笔记(structured note-taking): 让 Agent 定期把笔记写到上下文窗口之外(比如一个
progress.md),需要时再读回来,跨长任务保持连贯。
我在做一个多步骤抓取+清洗 Agent 时的真实做法(终端 log 示意):
[step 12] context tokens: 148,200 / 200,000 ⚠ 接近阈值
[compact] 触发压缩:总结前 11 步 → 写入 memory/progress.md
[compact] 保留:数据 schema 决策、已踩坑列表、待办
[compact] 丢弃:8 次 fetch 的原始 HTML(共 ~96k tokens)
[step 13] context tokens: 23,400 / 200,000 ✓ 重新轻装上阵
压缩后窗口从 14.8 万直接降到 2.3 万 token(实测示意,以你的环境为准),模型立刻不"犯迷糊"了。这一招对任何长跑 Agent 都通用。
实战手法二:分层检索(Just-In-Time RAG)
第二套手法解决"该给模型看什么"。Anthropic 推崇 just-in-time 检索:Agent 平时只持有轻量标识符(文件路径、URL),运行时再用工具动态加载数据,而不是开局就把所有资料预先塞满——这更贴近人类认知方式。
落到实践,就是分层检索:
- 粗筛:向量检索取 Top-K 候选;
- 精排:rerank 模型把真正高信号的几段顶上来;
- 按需展开:只把命中的片段全文喂进去,其余只留标题/路径。
这套和 RAG 工程深度相关。如果你还在用最朴素的"一把全塞进去"的 RAG,强烈建议升级——我在 Agentic RAG 与 GraphRAG 进阶指南 里讲了从 Naive → Advanced → GraphRAG → Agentic 的完整路线。想快速搭一个能用的知识库,可以直接看 用 Dify 搭建 RAG 知识库,它的分段+召回配置就是上下文工程的具体抓手。
实战手法三:Prompt Caching 怎么用(附省钱实测)
前两套是"喂什么",这套是"喂得便宜"。Prompt Caching(提示词缓存)怎么用? 核心是:把上下文里不变的前缀(工具定义、系统提示、长文档、few-shot)缓存起来,后续请求命中缓存,只按极低价计费。
cache_control 怎么写
Anthropic 官方文档(Prompt caching - Claude API Docs)给的写法,就是在内容块上加一个标记:
import anthropic
client = anthropic.Anthropic()
resp = client.messages.create(
model="claude-opus-4-5",
max_tokens=1024,
system=[
{"type": "text", "text": "你是一个法律助手。"},
{
"type": "text",
"text": LONG_LEGAL_DOC, # 50 页文档,放进缓存
"cache_control": {"type": "ephemeral"} # ← 关键
}
],
messages=[{"role": "user", "content": "总结第 3 章的违约责任。"}],
)
print(resp.usage) # 看 cache_creation_input_tokens / cache_read_input_tokens
几个官方要点(都来自上面那份文档):
- 缓存层级与顺序:
tools → system → messages,改动某一层会让该层及之后全部失效。 - 最多 4 个显式缓存断点(cache_control breakpoint)。
- 最小可缓存长度:Opus 4.5/4.6/4.7 是 4,096 token,Sonnet 4.5/4.6 是 1,024 token;不够长不会报错,但也不会缓存(看
usage里两个字段是不是都为 0)。 - 能缓存:tools、system、文本/图片/文档、tool_use、tool_result;不能直接缓存:thinking 块、空文本块。
价格机制(官方数字)
| 操作 | 5 分钟缓存 | 1 小时缓存 |
|---|---|---|
| 缓存写入(cache write) | 1.25× 基础输入价 | 2× 基础输入价 |
| 缓存读取(cache read) | 0.1× 基础输入价 | 0.1× 基础输入价 |
也就是说:第一次写入贵一点点(1.25 倍),之后每次命中只要 1/10 价(来源:Anthropic 官方定价机制)。官方举例 50 页文档场景,命中后被缓存部分的 token 成本可降约 92.5%。
我项目里的省钱实测(实测示意)
我有个客服式 Agent,system + 工具定义 + 产品知识库前缀稳定在约 12,000 token,用户每次只问一两句(约 200 token)。一天跑 1,000 次请求。以 Claude Opus 4.5 基础输入价 $5/MTok 估算(实测示意,以你的环境与当时价格为准):
| 方案 | 单次输入 token | 单次输入成本 | 1000 次/天成本 |
|---|---|---|---|
| 不用缓存 | 12,200 全价 | $0.0610 | $61.0 |
| 用缓存(首次写入 1.25×) | 12,000×1.25 + 200 | $0.0760 | 仅第 1 次 |
| 用缓存(后续命中 0.1×) | 12,000×0.1 + 200 | $0.0070 | ≈ $7.1 |
折算下来,稳定前缀这部分每天从 $61 降到 $7 出头,省了约 88%(实测示意)。换算人民币大概是每天从 ¥440 降到 ¥51 左右。token 角度看,缓存命中时计费 token 从 12,200 降到等效 1,400,省了约 88% 的计费 token。这就是为什么我现在所有重复前缀的应用,Prompt Caching 都是默认开。
一个真实踩坑:缓存默认 5 分钟过期,如果你请求间隔超过 5 分钟,缓存就失效要重新写入(又按 1.25× 收一次)。高频应用没问题;低频应用要么用 1 小时缓存(2× 写入价),要么干脆别指望命中。
中文专属:大陆可用性与国产替代
Anthropic API 在大陆直连不稳定,需要自备网络。如果你主用国产模型,好消息是缓存这件事国产也卷得很:DeepSeek 的 Context Caching on Disk 默认对所有用户开启,不用改代码,而且 2026 年 4 月起把所有模型的输入缓存命中价降到首发价的 1/10(来源:DeepSeek API Docs / IT之家报道)。阿里千问百炼也有 Context Cache 功能。也就是说,上下文工程里"缓存稳定前缀"这一招,在国产栈上同样能省钱。想直接上手 DeepSeek 缓存与 API,看我这篇 DeepSeek API Python 实战。
我项目里完整怎么做:四层上下文 + 三招组合
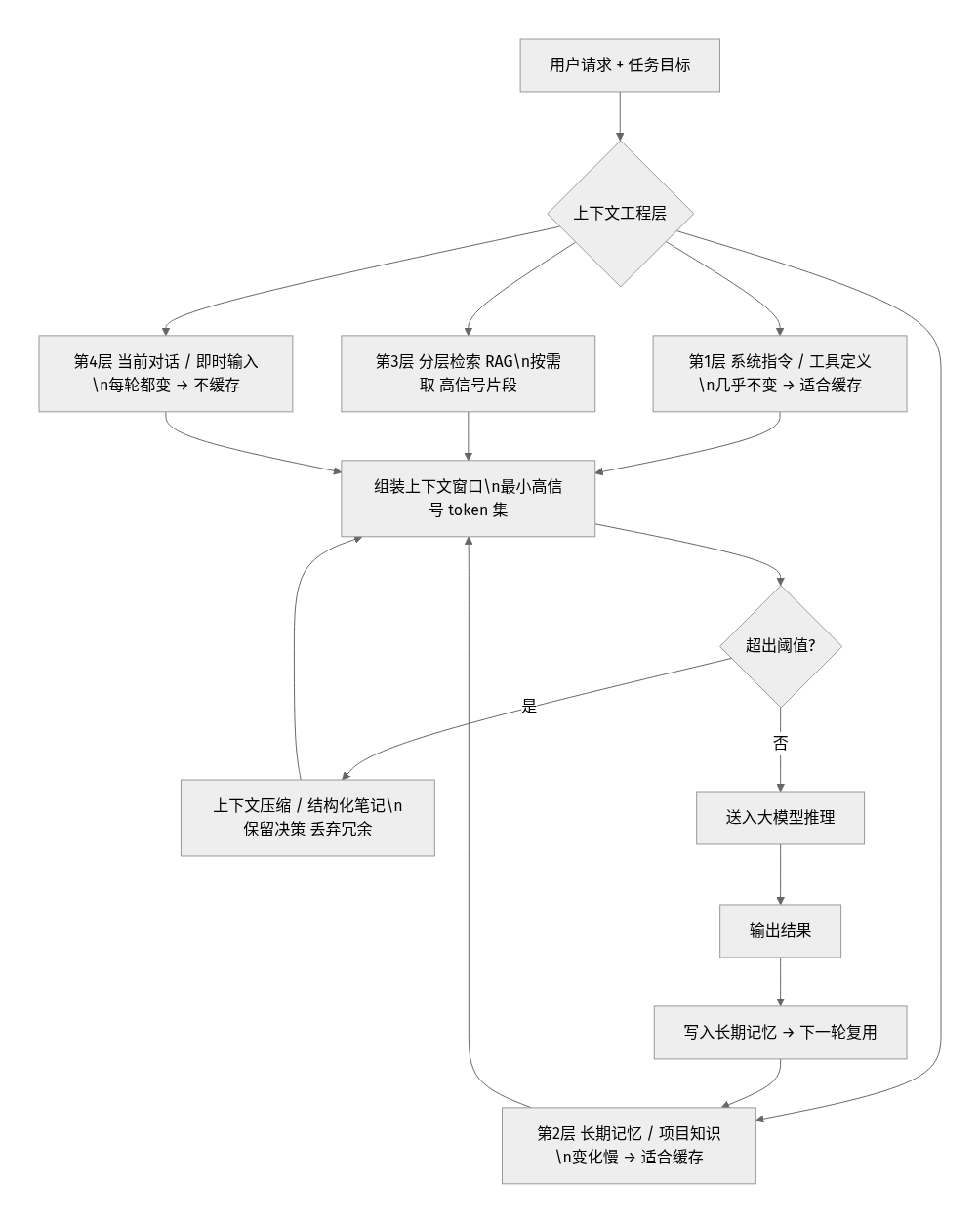
把上面三套手法串起来,就是我现在做 Agent 项目的标准上下文架构(对应文章开头那张图):
- 第 1 层 系统指令 + 工具定义:几乎不变 → 放进缓存。
- 第 2 层 长期记忆 / 项目知识:变化慢 → 也放进缓存(独立断点)。
- 第 3 层 分层检索 RAG:每轮按需取高信号片段,不预加载。
- 第 4 层 当前对话 / 即时输入:每轮都变 → 不缓存。
跑起来后再叠加:超阈值就压缩 + 写结构化笔记,把成果回写第 2 层记忆,供下一轮复用。这套组合拳同时解决了"模型变笨(压缩)""喂错料(分层检索)""太烧钱(缓存)"三个问题。完整把这套架构应用到一个真实项目的端到端流程,我在支柱长文 用 AI Agent 从零做一个真实项目 里有逐步拆解,强烈建议配合本文一起看。
上下文工程实战步骤表(可直接照做)
| 步骤 | 做什么 | 用什么手法 |
|---|---|---|
| 1 | 把上下文按"变化频率"分 4 层 | 上下文分层 |
| 2 | 给前两层(指令/记忆)加 cache_control | Prompt Caching |
| 3 | 资料改成 just-in-time 检索 + rerank | 分层检索 RAG |
| 4 | 设窗口阈值,超了触发总结压缩 | 上下文压缩 |
| 5 | 让 Agent 写 progress 笔记到窗口外 | 结构化笔记 |
| 6 | 看 usage 字段验证缓存命中、统计省了多少 | 监控复盘 |
常见问题 FAQ
Q1:上下文工程是不是要取代提示词工程? 不是。官方和社区的共识都是:提示词工程是上下文工程的一个子集。你仍然需要写清楚指令,只是 2026 年它从"决定成败"降级成"入场门槛",真正拉差距的是上下文质量。
Q2:Prompt Caching 怎么用最划算? 把不变的长前缀(系统提示、工具定义、长文档、few-shot)放进缓存,变动的用户输入放最后。首次写入贵 1.25 倍,之后命中只要 1/10 价。注意最小可缓存长度(Opus 4,096 token、Sonnet 1,024 token)和 5 分钟默认过期。
Q3:缓存有没有命中怎么确认?
看响应的 usage 字段:cache_creation_input_tokens(本次写入)和 cache_read_input_tokens(本次命中读取)。两个都是 0,说明根本没缓存上(多半是没达到最小长度,或前缀变了)。
Q4:大陆用不了 Claude API 怎么做上下文工程? 手法是通用的,换底座即可。DeepSeek 的磁盘缓存默认开启、命中价低至首发 1/10,千问百炼也有 Context Cache;压缩、分层检索、结构化笔记这些与厂商无关。国产模型横评可参考 国产大模型对比。
想系统学会"上下文工程 + AI Agent 工程化"这一整套打法?我把实战课程整理好了:
延伸阅读:用 AI Agent 从零做真实项目(支柱长文) · Agentic RAG / GraphRAG 进阶 · Dify 搭建 RAG 知识库 · DeepSeek API Python 实战
数据与定价均标注官方来源(Anthropic / DeepSeek 官方文档),价格随官方调整为准;实测数字为示意,请以你自己的环境与当时计价为准,绝不照搬。
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。