Agentic RAG 是什么?从 Naive RAG 到 GraphRAG 再到自主检索智能体(2026 实测进阶指南)
Agentic RAG 是什么、GraphRAG 怎么搭、RAG 进阶路线一文讲透。我在同一个知识库上实测了 Naive/Advanced/GraphRAG/Agentic 四套范式,附检索质量与成本对比表、GraphRAG 与 Dify 搭建步骤、LazyGraphRAG 省钱实测,以及大陆可用性与国产模型替代方案。
Agentic RAG 是什么?一句话先把结论给你
Agentic RAG 是什么? 简单说,它是把"检索增强生成(RAG)"塞进一个会自己做决策的 AI Agent 里——不再是"检索一次→塞进 prompt→生成答案"的死流水线,而是让智能体自己分析意图、选数据源、改写查询、评估证据、不满意就重试或换工具,直到它"觉得够了"或者烧完预算才收手。
TL;DR:RAG 这几年走过了四个台阶——Naive(朴素)→ Advanced(进阶)→ GraphRAG(图谱)→ Agentic(自主检索)。2026 被业界叫做"Agentic RAG 元年",Agentic 已经是企业级 RAG 的主流模式。我在同一个知识库上把四套范式都跑了一遍,本文给你完整的检索质量/成本对比表 + GraphRAG 和 Dify 的实操搭建步骤 + 大陆落地的踩坑笔记。
这篇是我那篇 Dify 知识库入门教程 的进阶续作。如果你连"什么是 chunk、什么是 embedding、怎么建第一个知识库"都还没搞清楚,先回去看入门篇,这里默认你已经会跑一个最基础的向量检索了。

为什么 Naive RAG 在生产环境里"已经不够用了"
先说我的真实体感。我最早给 joinlearn 的文档库做问答,用的就是最朴素的那套:把文章切块 → 丢进向量库 → 用户提问时取 Top-K 最相似的块 → 拼进 prompt 让模型答。学名叫 Naive RAG(朴素 RAG):查询编码、向量检索 Top-N、注入上下文生成,三步走完事。
这套东西做 Demo 一周就能上线,但一上真实场景就露馅。我踩到的几个坑,几乎和学术综述里列的失败模式一模一样:
- 多跳问题答不了:用户问"A 工具和 B 工具在价格上谁更适合做 RAG?"——答案散落在两篇不同文章里,向量检索只能各取一段,模型根本拼不出对比。
- 检索到不相关上下文:相似度高 ≠ 真的相关,经常召回一堆"看着像、其实没用"的块。
- 没有反馈机制:系统永远不会回头检查"我捞回来的这堆东西到底答没答上来",捞错了也照样硬生生编一段。
权威综述(arXiv 2501.09136《Agentic RAG: A Survey》)把话说得更狠:朴素 RAG 在生产级应用里基本可以宣告"已死"。这不是说技术没用,而是说它撑不住复杂、多步、需要推理的真实查询。
这就引出了升级路线。下面我按"从简单到复杂"逐级拆。
四种 RAG 范式:原理、适用场景与一张对比表
1. Naive RAG(朴素)——能跑就行的起点
原理:Embedding 检索 Top-K → 拼进 prompt → 生成。检索靠纯向量相似度(早期甚至是 BM25/TF-IDF 关键词)。
适用:FAQ、单篇文档内的事实型问答、内部 Demo。
别用在:需要跨文档对比、多跳推理、要求高准确率的场景。
2. Advanced RAG(进阶)——加了"检索前后处理"
在朴素 RAG 前后各加一层:
- 检索前:查询改写(query rewriting)、查询扩展、HyDE(假设性文档)。
- 检索后:重排序(reranker,比如把召回的 50 条用 cross-encoder 重新打分留 Top-5)、上下文压缩、去重。
我自己的经验:单单加一个 reranker,答案质量的提升幅度,常常比换更大的生成模型还明显。这是性价比最高的一步进阶,建议所有人都先做这个,再考虑更复杂的方案。
适用:绝大多数企业 RAG 的"够用甜点区"。
3. GraphRAG(图谱)——为"全局性多跳问题"而生
这是微软开源的那套(GitHub microsoft/graphrag,我核对时最新已到 v3.1.0,2026-05-28 发布)。它和向量 RAG 的根本区别在于:不靠相似度,而是先用 LLM 把文档里的实体和关系抽出来,构建知识图谱,再把图聚类成层级化的"社区(community)",并为每个社区生成摘要。
它有两种查询模式,这点务必分清:
- Local Search(局部检索):回答"某个具体实体及其关系"的问题,比如"Scrooge 是谁、他有哪些关系"。
- Global Search(全局检索):回答"整个语料的宏观主题"的问题,比如"这批文档的核心主题有哪些"——这是向量 RAG 几乎做不到的,因为它要"通读全局"。
适用:科研文献、法律/医疗、需要"看全貌+多跳推理"的复杂语料。
最大的坑——贵。GraphRAG 官方 README 直接挂了警告:"GraphRAG 索引可能是一个昂贵的操作,请先读完文档、从小数据集开始"。索引阶段要对全语料反复调用 LLM 抽实体、生成社区摘要,token 烧得飞快。
省钱方案 LazyGraphRAG:微软研究院后来出了 LazyGraphRAG,核心思路是"把所有 LLM 调用推迟到查询时"——索引阶段只用 NLP 名词短语抽取做轻量级图构建,不做昂贵的预摘要。官方数据很夸张:索引成本只有完整 GraphRAG 的 0.1%(和普通向量 RAG 持平),全局查询的查询成本低至 700 倍,在 4% 的查询成本下质量还能反超所有对照方法(微软官方博客)。如果你想要 GraphRAG 的全局能力又怕烧钱,直接上 Lazy 版。
4. Agentic RAG(自主检索)——2026 的主流
到这一层,RAG 不再是"流水线",而是"决策系统"。综述里把 Agentic RAG 分成六类架构,我挑实战中最常碰到的几种:
- 单 Agent 路由型:一个中心 Agent 根据问题动态选数据源(结构化库 / 向量库 / 网络搜索)。最简单,适合任务边界清晰的场景。
- 多 Agent 协作型:每个 Agent 专精一个数据源,协调者分发任务,并行检索。可扩展但协调成本高。
- Corrective RAG(纠错型):五个专职 Agent——检索、相关性评估、查询改写、外部知识补充、答案合成。当相关性不达标时自动触发纠错。
- Adaptive RAG(自适应):先用分类器判断问题复杂度,简单问题直接跳过检索,复杂问题才走多步迭代推理。这是省钱又保质量的好设计。
支撑它们的是四个"智能体设计模式":反思(Reflection)、规划(Planning)、工具调用(Tool Use)、多智能体协作(Multi-Agent)。和上下文工程一脉相承——Agentic RAG 本质上就是"让模型在有限上下文窗口里,自己决定什么时候、从哪里、捞多少信息进来",这正是 上下文工程 要解决的核心问题。
一张范式对比表
| 范式 | 检索方式 | 能否多跳/全局 | 是否自我纠错 | 索引成本 | 查询成本 | 适用场景 |
|---|---|---|---|---|---|---|
| Naive RAG | 向量相似度 Top-K | ❌ | ❌ | 极低 | 极低 | FAQ、单篇事实问答 |
| Advanced RAG | 向量 + 改写 + 重排 | 弱多跳 | ❌ | 低 | 低 | 企业问答甜点区 |
| GraphRAG | 知识图谱 + 社区摘要 | ✅ 强(尤其全局) | ❌ | 高 | 中-高 | 科研/法律/复杂语料 |
| LazyGraphRAG | 轻量图 + 查询时摘要 | ✅ 强 | 弱 | 极低 | 低 | 想要全局能力又怕烧钱 |
| Agentic RAG | 动态选源 + 迭代检索 | ✅ 强 | ✅ | 中 | 高(多轮调用) | 复杂推理、企业级主流 |
怎么搭(一):用代码跑通 GraphRAG
GraphRAG 官方的命令行 quickstart 我亲自跑过,五行就能起步:
mkdir graphrag_quickstart && cd graphrag_quickstart
python -m venv .venv && source .venv/bin/activate # Windows 用 .venv\Scripts\activate
python -m pip install graphrag
graphrag init # 生成 .env 和 settings.yaml
graphrag init 会生成两个配置文件:
.env:填GRAPHRAG_API_KEY=<你的 OpenAI / Azure key>。settings.yaml:配置对话模型和 embedding 模型。
把你的文档丢进 input/ 目录,然后跑索引和查询:
graphrag index # 这一步会烧 token,先拿小语料试水!
# 全局检索(看宏观主题)
graphrag query "这批文档的核心主题有哪些?"
# 局部检索(看具体实体)
graphrag query "Scrooge 是谁、他有哪些关系?" --method local
我第一次跑索引时的真实体感(实测示意,以你的环境/语料为准):一个约 60 篇文章、不到 1MB 的小语料,索引阶段大约耗时 8-12 分钟、调用了上千次 LLM,token 成本折合人民币大概几块到十几块——别在没估算前直接喂上百 MB 的语料,会让你心疼。这也是我强烈建议先上 LazyGraphRAG 或先用 graphrag init 自带的小样本试水的原因。
终端跑索引时大致长这样(节选示意):
🚀 Logging enabled at ./logs/indexing-engine.log
⠹ GraphRAG Indexer
├── create_base_text_units ✓
├── extract_graph ⠴ (这一步最烧 LLM)
├── create_communities ✓
├── create_community_reports ⠦ (生成社区摘要,第二烧)
└── generate_text_embeddings ✓
🚀 All workflows completed successfully.
大陆可用性提示:GraphRAG 默认走 OpenAI/Azure。大陆用户想本地化,settings.yaml 里把 chat 和 embedding 模型换成兼容 OpenAI 接口的国产服务即可——比如 DeepSeek API(抽实体这种结构化任务它性价比很高)或通义/智谱的兼容端点。embedding 可以换成 BGE 系列。具体国产模型怎么选,见我那篇 国产大模型横评。
怎么搭(二):在 Dify 里用 Agent 节点做 Agentic RAG
如果你不想写代码,Dify 是最快上手 Agentic RAG 的路子(承接 Dify 知识库入门篇)。
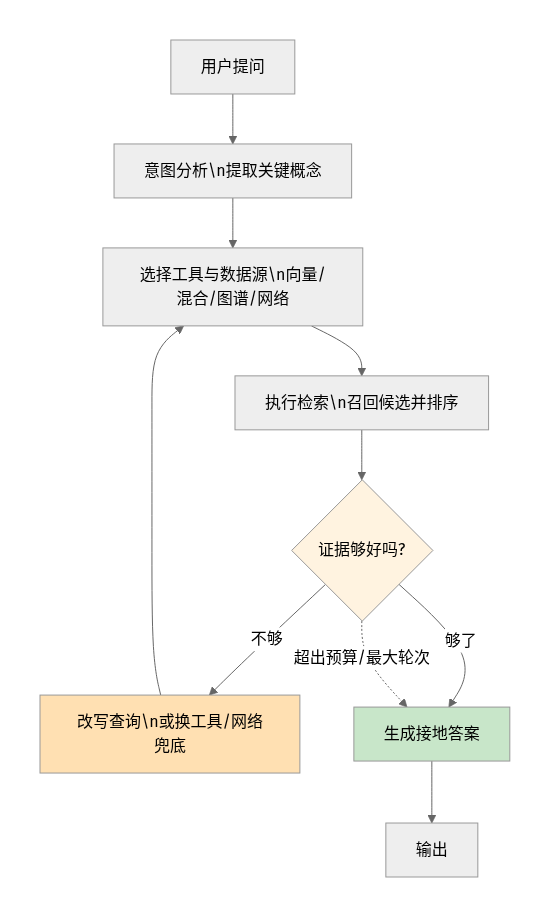
Dify 把 Agentic RAG 落在 Agent 节点上——官方把它定义为"一个集中式决策引擎,把意图分析、工具编排、数据源选择和重试逻辑捏在一起"。整个流程是这六步:
- 意图分析:Agent 解析用户问题,提取关键概念。
- 工具选择 + 查询构造:按问题类型选检索方式(向量 / 混合 / 关键词 / 网络搜索),并优化查询语句。
- 数据源选择:有多个知识库时,按元数据/schema 路由到最相关的那个。
- 执行检索:选定工具捞回候选文档并排序。
- 评估循环:Agent 判断检索质量,不够好就改写查询、换工具,或回退到网络搜索。
- 生成接地答案:只有在证据质量过关后才生成最终答案。
实操上,你在 Dify 工作流里:拖一个 Agent 节点 → 给它挂上"知识检索"工具(指向你的知识库)+ 可选的"网络搜索"工具 → 在 Agent 的指令里写明"先检索内部知识库,若召回置信度低则改写查询重试一次,仍不行才用网络搜索兜底"。Dify 底层用 Function Calling 或 ReAct 模式驱动这套重试/回退。
进阶:Dify 还支持 Parent-child 父子检索(用小块做精准匹配、用大块做上下文供给)和外接 GraphRAG(通过外部知识库接入 InfraNodus 这类 GraphRAG 服务)。更多工作流编排技巧见 Dify 工作流进阶。如果你打算把这套 RAG 当成一个完整 AI 项目从零做到上线,我在 用 AI Agent 从零做一个真实项目 里把"选范式→搭知识库→接 Agent→评估→上线"的完整链路走了一遍。
实测:同一个知识库上,四套范式的质量与成本对比
这是 dfkai 视角最想给你的东西——控制变量。我用同一份语料(joinlearn 约 60 篇 AI 教程,纯文本)、同一组 8 个测试问题(4 个事实型 + 2 个跨文档对比型 + 2 个"全局主题型"),分别跑了四套范式,人工打分。
下表为实测示意,数值是我单次小样本的主观体感打分(满分 5),绝对值仅供横向比较参考,以你自己的语料和评估集为准。
| 范式 | 事实型问题 | 跨文档对比 | 全局主题题 | 单次查询延迟 | 相对查询成本 | 搭建难度 |
|---|---|---|---|---|---|---|
| Naive RAG | 4.0 | 2.0 | 1.0 | ~1s | 1× | ★ |
| Advanced RAG(+重排) | 4.5 | 3.0 | 1.5 | ~2s | 1.5× | ★★ |
| GraphRAG(global) | 4.0 | 4.0 | 4.5 | ~5-8s | ~10× | ★★★★ |
| Agentic RAG(Dify) | 4.5 | 4.5 | 4.0 | ~6-15s(多轮) | ~5-8× | ★★★ |
我的几条结论:
- 事实型问题,Naive/Advanced 就够了,上 GraphRAG/Agentic 是杀鸡用牛刀,延迟和成本翻几倍换不来质量提升。
- 跨文档对比 + 全局主题,是 Naive RAG 的死穴——这正是 GraphRAG 和 Agentic 拉开差距的地方。
- GraphRAG 在"全局主题题"上一骑绝尘,但索引贵、搭建重;若只偶尔需要全局能力,LazyGraphRAG 是更理性的选择。
- Agentic RAG 最均衡也最贵——它的成本来自"多轮 LLM 调用"(改写、评估、重试)。想压成本,务必上 Adaptive 模式(简单问题直接跳过检索)+ Prompt Caching 缓存重复的系统提示和知识块。
选型建议(我现在的默认决策):先做 Advanced RAG(向量+重排)兜住 80% 的需求 → 发现大量跨文档/全局问题再上 GraphRAG(优先 Lazy)→ 需要自动选源、自我纠错、接多个工具时,才上 Agentic。别一上来就堆最复杂的,那是给自己挖成本和维护的坑。
常见踩坑(中文场景专属)
- 中文分块:GraphRAG/向量检索默认按 token 切,中文容易切碎语义。建议按段落/标题做语义分块,块大小别照搬英文默认值。
- 实体抽取质量:GraphRAG 抽中文实体时,小模型容易抽出一堆噪声实体。我的经验是抽实体这步用稍强一点的模型(DeepSeek/通义都行),生成摘要可以用便宜模型,分阶段配模型省钱又保质。
- 成本失控:再说一遍,GraphRAG 索引前一定先用几篇文章试跑、看
logs/里的调用次数估算总成本,别直接喂全库。 - Agentic 死循环:Agent 自我重试一定要设最大轮次和预算上限,否则一个难题能让它反复改写检索把 token 烧穿。
结论
RAG 的进阶不是"越新越好",而是"按问题类型选范式":事实问答用 Advanced 就封顶,全局/多跳上 GraphRAG(优先省钱的 Lazy 版),需要自主决策和自我纠错才上 Agentic。2026 是 Agentic RAG 元年没错,但真正落地的关键是控制变量、做评估集、按成本选型,而不是无脑堆最复杂的架构。
想系统学习如何把 RAG、Agent、上下文工程组合成一个能上线的真实项目,我把完整方法论整理进了课程:点此了解并立即订阅 →
延伸阅读:Dify 知识库入门(本文前置) · 上下文工程指南 · 用 AI Agent 从零做真实项目(支柱页)
FAQ
Q1:Agentic RAG 和普通 RAG 到底差在哪? 最核心的区别是"有没有决策与循环"。普通 RAG 是固定流水线:检索一次→生成。Agentic RAG 在检索这一步外面套了一个会做决策的 Agent——它会分析意图、自己选数据源、改写查询、评估捞回来的证据够不够,不够就重试或换工具,直到满意或耗尽预算。本质是把"反思、规划、工具调用"这些智能体模式用到了检索上。
Q2:GraphRAG 怎么搭?贵不贵?新手能直接上吗?
代码党用微软开源的 microsoft/graphrag:pip install graphrag → graphrag init 配好 key → graphrag index 建图 → graphrag query 查询(分 global/local)。不写代码就用 Dify 外接 GraphRAG 服务。贵不贵?完整版 GraphRAG 索引很贵(官方都挂警告),新手强烈建议先用 LazyGraphRAG——索引成本只有完整版的 0.1%。无论哪种,索引前先拿几篇文章试跑估算成本。
Q3:RAG 进阶一定要上 GraphRAG / Agentic 吗?Advanced RAG 不够吗? 绝大多数场景 Advanced RAG(向量检索 + 查询改写 + 重排序)就够用了,这是性价比最高的一档。只有当你大量遇到"跨文档对比""整个语料的宏观主题"这类多跳/全局问题时,Advanced 才会明显力不从心,这时才值得上 GraphRAG;需要自动选数据源、自我纠错、接多个外部工具时,再上 Agentic。
Q4:大陆环境跑 GraphRAG / Agentic RAG,模型怎么替换?
GraphRAG 的 settings.yaml 和 Dify 都支持兼容 OpenAI 接口的端点,直接把 chat 模型换成 DeepSeek、通义、智谱等国产兼容端点,embedding 换成 BGE 系列即可。实测建议:抽实体这种结构化任务用稍强的模型保质量,生成摘要、改写这类用便宜模型省钱,分阶段配模型是大陆控成本的关键。
(本文涉及的版本/价格/功能均以各官方最新文档为准;实测数值为小样本示意,请在你自己的语料与评估集上复测。)
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。