Dify 教程:手把手搭一个本地知识库问答机器人(RAG 图解实战)
想让 AI 读懂你自己的文档来回答问题?本教程用零代码平台 Dify 手把手搭一个 RAG 知识库问答机器人:讲透 RAG 原理、文档分块与向量化、应用编排到发布上线,配 Mermaid 架构图解,非程序员也能跟着做。
你的 AI 不知道你自己的文档,怎么办?
ChatGPT、DeepSeek、豆包很强,但它们答不出"我们公司的报销流程是什么""这份 200 页的产品手册第 3 章讲了啥"——因为这些私有知识不在模型的训练数据里。硬塞进对话框?文档一长就超出上下文,每次还得复制粘贴,根本没法用。
解决办法是 RAG(检索增强生成,Retrieval-Augmented Generation):先把你的文档存进一个"可检索的知识库",每次提问时先从中检索出最相关的片段,再连同问题一起喂给大模型生成答案。这样 AI 就能基于你的私有资料、有理有据地回答。
这篇教程,我(dfkai)带你用 Dify(一个零代码的 AI 应用平台)从 0 搭一个能读你自己文档的知识库问答机器人。全程不用写代码,跟着点就行。
先搞懂 RAG 是怎么工作的
一句话:先检索、再回答。完整流程如下:

拆开看四步:
- 向量化(Embedding):把你的问题转成一串数字向量,代表它的"语义"。
- 检索:在知识库里找出语义最接近的文档片段(不是关键词匹配,是"意思相近")。
- 拼接上下文:把检索到的片段和你的问题,组成一个更完整的提示词。
- 生成:大模型基于这段上下文回答——所以答案有依据,不容易瞎编。
关键点:RAG 不改模型,只改"喂给模型的输入"。所以任何模型(DeepSeek、通义千问、GPT…)都能用,换模型也不影响你已经建好的知识库。
为什么用 Dify?
自己写 RAG 要处理分块、Embedding、向量数据库、检索逻辑、提示词编排一大堆,对非程序员门槛太高。Dify 把这些全做成了可视化操作——上传文档、点几下、绑定模型,就能发布成一个网页问答机器人或 API。这也是它适合作为你第一个 RAG 实战工具的原因。
实战:用 Dify 搭知识库问答机器人
整体分"知识准备"和"应用编排"两块:
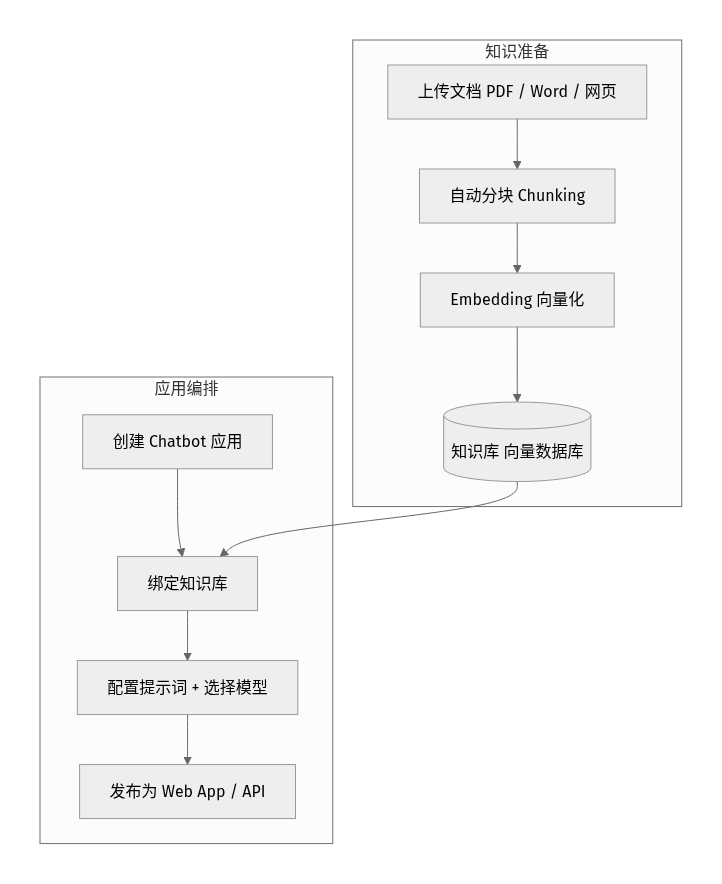
第 0 步:准备 Dify
两种方式选一种:
- 云端版:访问 Dify 官网注册,开箱即用,适合先体验。
- 自托管:用 Docker 在自己服务器部署,文档和数据不出本地,适合企业或隐私敏感场景。
第 1 步:创建知识库,上传文档
进入"知识库"→ 新建 → 上传你的文档(支持 PDF、Word、Markdown、网页等),Dify 会自动读取内容。
第 2 步:设置分块与索引方式(最容易踩坑)
这一步决定检索质量:
- 分块(Chunking):文档被切成小片段。片段太大→检索不精准;太小→丢失上下文。中文文档每块 300–500 字、留一点重叠是稳妥的起点。
- 索引模式:选"高质量"用 Embedding 做语义检索(推荐);"经济"模式用关键词,便宜但不准。
- Embedding 模型:选一个中文效果好的(如 bge、text-embedding 系列)。
第 3 步:创建 Chatbot 应用并绑定知识库
回到"工作室"→ 新建应用 → 选"聊天助手"→ 在"上下文"里关联刚才建好的知识库。这样机器人在回答前就会先去检索它。
第 4 步:配置提示词 + 选模型
- 提示词:给它设定角色和边界,例如"你是 XX 公司的客服助手,只根据知识库内容回答;知识库里没有的就说'暂未收录',不要编造。"——这一句能大幅降低幻觉。
- 模型:接入 DeepSeek、通义千问、OpenAI 等任一家的 API Key。RAG 场景下模型主要负责"组织语言",所以性价比高的国产模型完全够用。
第 5 步:调试与发布
在右侧调试窗口提几个你已知答案的问题,验证它"答得对、有依据"。没问题后点发布,就能拿到一个网页链接或 API,嵌进网站、做成内部工具都行。
常见坑(我踩过的)
- 检索不准:八成是分块太大或索引用了"经济"模式。先把块调小、切回"高质量"。
- 它还是瞎编:在提示词里明确"只依据知识库回答,没有就说不知道",并把召回数量、相关度阈值调高。
- 中文效果差:换一个中文友好的 Embedding 模型,比换生成模型更有效。
- 文档更新了答案没变:知识库内容更新后要重新索引。
小结
RAG 就是给大模型外挂一个"可检索的记忆"。用 Dify,你不写一行代码就能让 AI 读懂自己的资料。把这套跑通,你就掌握了做企业知识库、智能客服、个人第二大脑的核心能力。
想从"会搭一个"到"系统掌握 AI 应用开发与变现"?我把工具选型、RAG 与 Agent 实战、踩坑经验都整理进了系统课程,点此了解并立即订阅 →,帮你少走弯路。
相关阅读:Dify 工作流完全指南
常见问题(FAQ)
Q:RAG 和直接把文档发给 ChatGPT 有什么区别?
直接发受上下文长度限制、每次都要重发;RAG 把文档存成可检索的知识库,自动按需取用,支持海量文档、还能持续更新。
Q:搭 RAG 一定要会编程吗?
不需要。用 Dify 这类平台全程可视化操作,本教程就是零代码路线。
Q:用哪个大模型最好?
RAG 里模型负责"组织语言",国产模型(DeepSeek、通义千问)性价比很高就够用;检索质量更多取决于分块和 Embedding 模型。
Q:数据安全吗?
担心隐私就用 Docker 自托管 Dify,文档和向量库都留在你自己的服务器上。
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。