Dify 工作流进阶教程 2026:节点编排、案例与发布 API
实测向的 Dify Workflow 进阶教程:讲清 Workflow 与 Chatflow 的区别、六大常用节点用法,手把手编排"翻译→总结→分类"流水线,并发布成 API。含调试技巧与避坑清单。
从"会拖节点"到"会编排",中间隔着这篇
我用 Dify 做过不少东西:知识库问答、内部工具、给同事用的小应用。最开始我也是照着入门教程拖几个节点跑通就完事,但真要把它用到正经业务上,问题立刻就来了——节点之间变量传错、条件分支走不到预期分支、调用方拿到的 JSON 结构每次都不一样、发布成 API 之后线上报错却不知道卡在哪一步。
入门教程教你"能跑",但生产环境要的是"稳定、可调试、可复用"。这篇我把自己踩过的坑和常用套路整理出来,覆盖 Workflow 与 Chatflow 的区别、六个最常用的节点、一个能直接抄走的实战案例,以及怎么发布成 API、怎么调试避坑。
如果你还没建过应用、对知识库检索没概念,建议先看我之前那篇入门:Dify RAG 知识库教程,再回来看这篇会顺很多。
说明:Dify 迭代很快,节点名称、定价、模型支持随版本变化,本文讲的是思路和方法,具体配置项以你当前版本的官方文档为准。
Workflow 和 Chatflow,到底该选哪个
这是新手最容易混的地方。Dify 在创建应用时给了两种"编排型"应用:Workflow(工作流) 和 Chatflow(对话流)。它们底层都是节点编排,区别在于"有没有对话上下文"。
| 维度 | Workflow 工作流 | Chatflow 对话流 |
|---|---|---|
| 触发方式 | 一次性输入 → 一次性输出 | 多轮对话,带会话记忆 |
| 是否有上下文 | 无(每次独立执行) | 有(自动维护 conversation history) |
| 典型场景 | 批处理、文档处理、自动化任务、被其他系统调用 | 客服机器人、问答助手、需要追问的场景 |
| 输出形态 | 结构化结果(适合给程序消费) | 流式对话回复(适合给人看) |
| 起始节点 | Start | Start + 内置对话变量 |
我的判断标准很简单:如果调用方是"程序",选 Workflow;如果调用方是"人在聊天框里打字",选 Chatflow。
比如"把一篇文章翻译+总结+打标签"这种活,没有追问、输入输出都明确,就是 Workflow。而"用户来咨询产品、可能反复追问"这种,要记住前面说过什么,就用 Chatflow。两者的节点大部分通用,所以下面讲的节点知识两边都能用。
六个最常用的节点,先把它们吃透
Dify 节点很多,但日常 80% 的活靠下面这几个就够了。我按使用频率排个序。
1. LLM 节点
最核心的节点,负责调用大模型。关键点有三个:
- System / User 提示词分开写:System 放角色和规则,User 放具体任务和变量,别全塞一起。
- 用变量插值:在提示词里用
{{#节点ID.字段#}}引用上游输出,这是节点间传值的核心。 - 结构化输出:如果下游要解析,尽量让 LLM 直接输出 JSON,并在提示词里给出 schema 示例。新版本支持"输出格式"约束,能用就用,比自己正则抠稳得多。
2. 知识检索(Knowledge Retrieval)节点
从你建好的知识库里召回相关片段,喂给后面的 LLM。这就是 RAG 的"R"。常调的参数是 Top K(召回条数)和 Score 阈值。检索结果会作为一个数组变量传给下游,记得在 LLM 节点里引用它。
3. 条件分支(IF/ELSE)节点
做"分流"用的。它根据变量值把流程导向不同分支。常见判断:等于/包含/为空/大于。这是客服分流、内容分类后做不同处理的关键节点。 注意它只做"路由",不做计算。
4. 代码执行(Code)节点
当你需要做 LLM 不擅长的确定性逻辑时上它——比如字符串清洗、数组去重、日期格式化、把多个字段拼成特定结构。支持 Python3 和 Node.js。我的经验是:凡是"规则明确、不需要理解语义"的事,都交给 Code 节点,别浪费 token 让 LLM 算。
def main(text: str, category: str) -> dict:
# 简单清洗 + 组装输出,确定性逻辑交给代码而不是 LLM
cleaned = text.strip().replace("\n\n", "\n")
return {
"result": cleaned,
"tag": category.lower(),
"length": len(cleaned),
}
5. HTTP 请求节点
调外部 API 用的。比如把结果写进飞书表格、查个汇率、调你自己的后端接口。支持 GET/POST、自定义 Header 和 Body,返回的 body/status_code 都能作为变量往下传。避坑:超时和异常处理要想清楚,外部接口挂了别让整个工作流崩。
6. 变量聚合(Variable Aggregator)节点
这个新手常忽略,但分支多了就离不开它。当流程分了好几个分支、最后要汇到同一个出口时,用它把"不同分支产生的同名变量"合并成一个,下游就不用写一堆判断了。条件分支 + 变量聚合是黄金搭档。
实战:编排一条"翻译 → 总结 → 分类"流水线
讲再多不如跑一遍。下面这个案例我自己实际搭过,输入一段任意语言的文字,自动翻译成中文、生成摘要、再打上分类标签,最后输出结构化 JSON。整条链路用 Workflow 实现。

节点编排顺序如下:
第 1 步:Start 节点
定义一个输入变量 input_text(段落文本,类型选 Paragraph)。这是整条流水线的入口。
第 2 步:LLM 节点(翻译)
- System:
你是专业翻译,把输入内容准确翻译成简体中文,只输出译文,不要解释。 - User:
{{#start.input_text#}} - 输出变量记作
translated。
第 3 步:LLM 节点(总结)
- User 引用上一步:
请把下面内容总结成 3 句话以内的摘要:{{#llm_translate.translated#}} - 输出
summary。
第 4 步:LLM 节点(分类,结构化输出) 让它在固定类别里选一个,并强制输出 JSON:
请阅读以下摘要,从【科技 / 财经 / 生活 / 其他】中选出最合适的一个分类。
摘要:{{#llm_summary.summary#}}
只输出 JSON,格式如下:
{"category": "科技"}
第 5 步:Code 节点(组装最终输出) 把前面三步的结果拼成一个干净的 JSON,顺便兜底处理分类解析。
import json
def main(translated: str, summary: str, category_raw: str) -> dict:
try:
category = json.loads(category_raw).get("category", "其他")
except Exception:
category = "其他"
return {
"output": {
"translation": translated,
"summary": summary,
"category": category,
}
}
第 6 步:End 节点
把 Code 节点的 output 设为最终输出字段。这样调用方拿到的永远是同一个结构。
这条链路的设计要点:语义任务交给 LLM,结构化/兜底逻辑交给 Code 节点。 这样既保证了灵活性,又保证了输出格式稳定——这是能不能上生产的分水岭。
如果你要做的是"客服分流",把第 4 步换成条件分支节点:根据用户意图(咨询/投诉/退款)走不同分支,每个分支接不同的 LLM 或 HTTP 节点处理,最后用变量聚合节点汇总输出即可,思路完全一样。
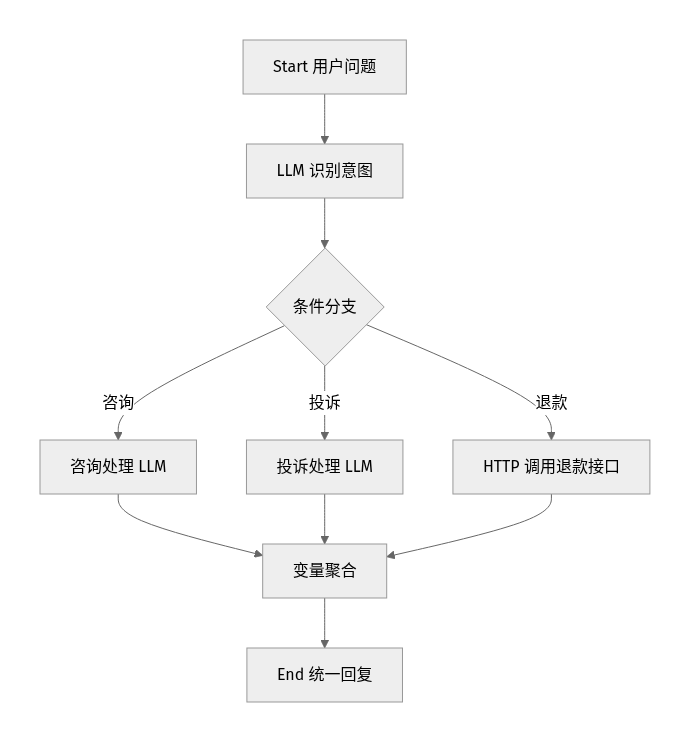
调试与发布成 API
调试:善用单步运行和运行历史
- 单步运行:右键单个节点可以单独跑,输入造个假数据,立刻看这个节点的输入输出对不对。我排查变量传错基本都靠它。
- 运行(Run)面板:整条跑完后,左侧能看到每个节点的实际入参、出参、耗时和 token 消耗。哪一步变量是空的、哪一步 JSON 解析炸了,一眼就能定位。
- 看变量引用:90% 的"流程不通"都是变量引用写错了节点 ID,或者上游字段名改了下游没更新。
发布成 API
确认无误后点右上角"发布"。Workflow 类应用会暴露一个 workflow/run 接口,Chatflow 是 chat-messages 接口。在"访问 API"页面能拿到 API Key 和文档。一个最小调用长这样:
curl -X POST 'https://api.dify.ai/v1/workflows/run' \
-H 'Authorization: Bearer {你的_API_KEY}' \
-H 'Content-Type: application/json' \
-d '{
"inputs": { "input_text": "Bitcoin hit a new milestone today." },
"response_mode": "blocking",
"user": "user-123"
}'
几个实测要点:
inputs里的 key 必须和 Start 节点定义的变量名一模一样。response_mode选blocking(等全部跑完一次性返回)或streaming(流式)。批处理任务用 blocking 更省心。user字段是必填的,传一个能标识终端用户的字符串即可。- 域名按你的部署来:用官方云就是
api.dify.ai,自托管换成你自己的地址。
避坑清单(都是我真踩过的)
- 变量引用是头号杀手:改了上游节点名或字段后,下游引用不会自动跟着改,发布前务必单步验证。
- LLM 输出别裸信任:让它出 JSON 后,下游一定要用 Code 节点 try/except 兜底,否则偶尔一次格式跑偏就会让整条流水线返回错误。
- token 成本失控:每个 LLM 节点都在烧 token,能用 Code 节点解决的别叫模型;摘要、分类这类任务用便宜的小模型就够,不用顶配模型。
- HTTP 节点要做异常处理:外部接口超时或返回非 200,要么加判断分支,要么接受工作流失败,别让它静默吞错。
- Workflow 没有记忆:别指望它记住上一次调用的内容,需要上下文请用 Chatflow 或自己在 inputs 里把历史传进去。
- 并发与限流:发布成 API 后被高频调用,注意模型供应商的限流,必要时在调用方加重试和排队。
小结
Dify 工作流的进阶,本质是三件事:选对应用类型(Workflow vs Chatflow)、把节点职责分清楚(语义给 LLM、规则给 Code)、保证输出结构稳定可被程序消费。 把"翻译→总结→分类"这条链路亲手搭一遍,你基本就掌握了大部分常见编排模式,后面无论是客服分流还是文档批处理,都是同一套思路的变体。剩下的就是多用单步调试,把每个节点的输入输出盯死,生产环境的稳定性自然就上来了。
FAQ
Q:Workflow 和 Chatflow 能互相转换吗? 不能直接一键转换。两者起始节点和上下文机制不同,需要重新创建对应类型的应用再把节点逻辑搬过去。所以一开始就想清楚调用方是"程序"还是"对话用户",避免返工。
Q:节点之间怎么传值,为什么我引用的变量是空的?
靠变量插值 {{#节点ID.字段名#}} 传值。变量为空通常是三种原因:引用了错误的节点 ID、上游字段名改过没同步、上游节点根本没执行到(比如被条件分支跳过了)。用单步运行逐个节点验证最快。
Q:发布成 API 后,输出结构每次不一样怎么办? 大概率是直接把 LLM 节点的原始输出当成了最终结果。正确做法是在 End 之前加一个 Code 节点,把字段组装成固定 schema 并对 LLM 的 JSON 做兜底解析,让 End 永远输出同一个结构。
Q:自己服务器部署的 Dify,API 地址和云端一样吗? 不一样。自托管时把请求域名换成你自己的部署地址(比如内网或自有域名),路径和参数结构相同。API Key 也要在你自己的实例里生成,不能用官方云的 Key。具体以你部署版本的官方文档为准。
想系统地把 Dify、RAG、AI Agent 这套工具链从入门用到落地,我把实测过的方法整理成了一套课程:点此了解并立即订阅 →
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。