DeepSeek API 调用教程:Python 从 0 上手(附完整可运行代码)
手把手用 Python 调用 DeepSeek API:拿 Key、第一个请求、用 OpenAI SDK、流式输出、多轮对话、计费与避坑,代码可直接复制运行。DeepSeek 兼容 OpenAI,便宜又好用。
为什么要用 API,而不是网页版?
网页版适合随手问问题,但一旦你想批量处理、接入自己的程序、做自动化——比如批量总结 100 篇文档、给自己的网站加个智能客服、写个自动回邮件的脚本——就必须用 API。API 就是让你的代码直接和 DeepSeek 模型对话的通道。
好消息:DeepSeek 的 API 完全兼容 OpenAI 的格式,所以你几乎不用学新东西,网上海量的 OpenAI 教程代码改个地址就能跑。这篇我(dfkai)带你从拿 Key 到流式输出、多轮对话,一步步把 DeepSeek API 跑通。
整体调用流程
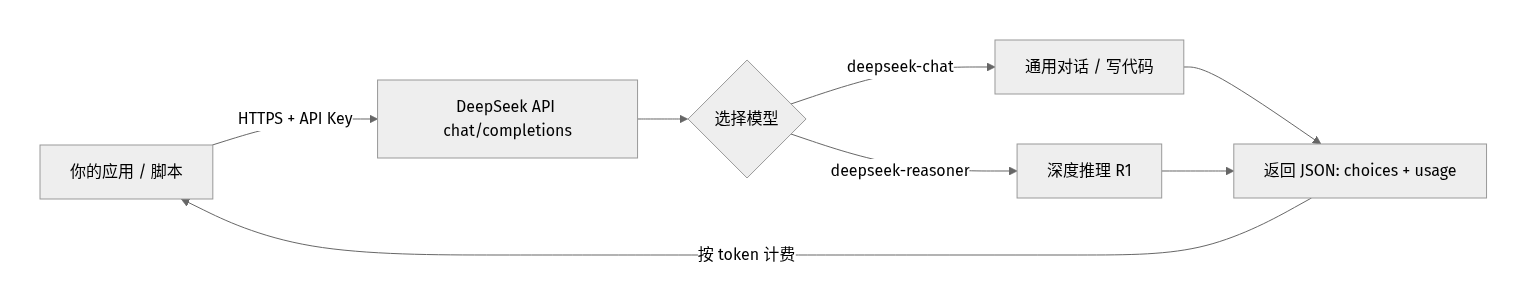
一句话:你的代码带着 API Key 发一个 HTTPS 请求,DeepSeek 返回 JSON 结果,按消耗的 token 计费。
第 1 步:拿到 API Key
- 打开 DeepSeek 开放平台(platform.deepseek.com),用手机号注册登录。
- 进入"API Keys"页面,点"创建 API Key",立刻复制保存(它只显示一次)。
- 到"充值"页面充一点额度(DeepSeek 很便宜,充 ¥10 够你测很久)。
⚠️ API Key 等于你的钱包密码,绝不要写死在代码里上传到 GitHub,也别发给别人。下面会讲怎么用环境变量安全保存。
第 2 步:发出第一个请求(Python + requests)
先用 pip 安装 requests,然后:
import os
import requests
# 从环境变量读 Key(安全做法,别写死在代码里)
api_key = os.environ["DEEPSEEK_API_KEY"]
resp = requests.post(
"https://api.deepseek.com/chat/completions",
headers={"Authorization": "Bearer " + api_key},
json={
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一个简洁的助手。"},
{"role": "user", "content": "用一句话解释什么是 API。"},
],
},
timeout=60,
)
data = resp.json()
print(data["choices"][0]["message"]["content"])
先把 Key 设进环境变量(终端里执行 export DEEPSEEK_API_KEY=你的key),运行就能看到模型回答。
第 3 步:用 OpenAI SDK 调用(更省心)
因为兼容 OpenAI,直接用 openai 这个库更方便。安装 openai 后:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com", # 关键:把地址指向 DeepSeek
)
resp = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "写一首关于秋天的两行诗。"},
],
)
print(resp.choices[0].message.content)
只要把 base_url 指向 DeepSeek,所有 OpenAI 的示例代码都能直接复用——这是 DeepSeek API 最大的便利。
关键参数怎么选
- model:deepseek-chat 是通用对话/写代码的主力(快、便宜);deepseek-reasoner 是深度推理模型(R1),擅长数学、逻辑、复杂分析,但更慢更贵。简单任务用 chat,难题用 reasoner。
- messages:对话历史数组,每条有 role(system / user / assistant)和 content。
- temperature:0 到 2,越低越稳定保守,越高越发散有创意。写代码、抽取信息用 0
0.3,写文案用 0.71。 - max_tokens:限制回答长度,防止太长烧钱。
- stream:是否流式输出(见下)。
第 4 步:流式输出(打字机效果)
默认要等模型全部生成完才返回,长回答会让用户干等。设 stream=True 就能像 ChatGPT 那样一个字一个字往外蹦:
stream = client.chat.completions.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "讲讲为什么天是蓝的。"}],
stream=True,
)
for chunk in stream:
delta = chunk.choices[0].delta.content
if delta:
print(delta, end="", flush=True)
做聊天机器人、网页应用时,流式输出体验好很多。
第 5 步:多轮对话(让它记住上文)
模型本身没有记忆,所谓"记住上文"是你每次把完整对话历史都发过去。做法:把模型的回复 append 回 messages,下次一起发:
messages = [{"role": "system", "content": "你是一个耐心的老师。"}]
def ask(question):
messages.append({"role": "user", "content": question})
resp = client.chat.completions.create(model="deepseek-chat", messages=messages)
answer = resp.choices[0].message.content
messages.append({"role": "assistant", "content": answer})
return answer
print(ask("什么是向量?"))
print(ask("那它在 AI 里有什么用?")) # 它能理解"它"指代向量
注意:对话越长,每次发送的 token 越多、越贵,可以定期裁剪最早的几轮。
计费与成本
DeepSeek 按 token(粗略:1 个汉字约 1-2 token)计费,分输入和输出两部分,deepseek-chat 比国外主流模型便宜一个数量级。还有一个杀手锏:上下文缓存——重复的前缀(比如固定的 system 提示)命中缓存后输入价格大幅下降,做知识库、客服这种 system 很长的场景特别省。每次响应的 usage 字段会告诉你这次用了多少 token。
常见坑
- 401 未授权:Key 错了、过期了、或没充值;检查环境变量是否真的读到了。
- Key 泄露:务必用环境变量、别提交进 Git;一旦泄露立刻去平台吊销重建。
- 超时 / 限流:加 timeout、做重试;并发高了会限流,降速或申请提额。
- reasoner 不返回 content:推理模型的思考过程在 reasoning_content 字段,最终答案才在 content,别取错。
- 回答被截断:max_tokens 设太小了,调大。
小结
DeepSeek API 的核心就三件事:带 Key 发请求 → 选对 model → 维护 messages。因为兼容 OpenAI,你能直接复用整个生态的代码和工具。把这套跑通,你就能给任何应用接上一个又快又便宜的中文大模型。
想系统学会把 AI 接进自己的产品、做出能变现的东西?我把 API、Agent、全栈实战和变现路径都整理进了系统课程,点此了解并立即订阅 →,帮你少走弯路。
常见问题(FAQ)
Q:DeepSeek API 收费吗?有免费额度吗?
按 token 付费,价格很低;注册后充少量额度即可长期测试,具体价格以平台为准。
Q:一定要用 Python 吗?
不是。API 是标准 HTTP,任何语言(JS、Go 等)都能调;因为兼容 OpenAI,用各语言的 OpenAI SDK 改 base_url 最省事。
Q:deepseek-chat 和 deepseek-reasoner 怎么选?
日常对话、写代码、总结用 chat(快、便宜);数学、逻辑推理、复杂分析用 reasoner。
Q:怎么保护我的 API Key?
用环境变量读取,不要写进代码或提交到 GitHub;前端项目尤其不能把 Key 放浏览器端,要通过你自己的后端中转。
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。