Claude Code Subagents + Agent Teams 多智能体并行实战(2026)
claude code subagents 教程实测:用 subagents 分工 code review/写测试/写文档,claude agents 一屏管 N 个 agent,/workflows 后台编排数百智能体。含真实终端 log、并行翻车收口踩坑、成本数字。
Claude Code Subagents + Agent Teams:一个人开一支 AI 军团
claude code subagents 教程这个搜索词最近的热度,几乎是被 Anthropic 自己推高的——2026 年 5 月这一个月里,Claude Code 把"多智能体并行"从玩具级功能升级成了生产级编排:subagents 分工、claude agents 一屏总览、/workflows 后台跑数百个 agent。我 dfkai,过去两周把这套东西在自己的真实项目里翻来覆去用了一遍,踩了坑也尝了甜头。
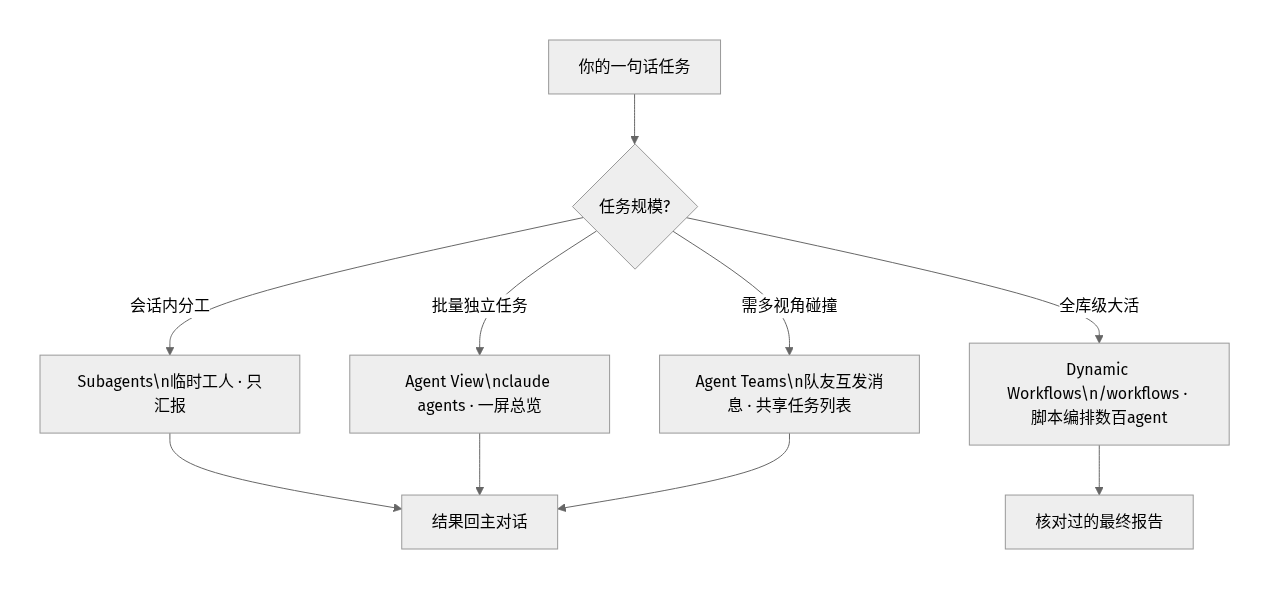
TL;DR 结论先放这: 日常分工(code review / 写测试 / 写文档)用 subagents 就够了,零配置、低成本;要同时盯十几个独立任务、不想被终端刷屏,用 claude agents(Agent View);真正的大活儿(全库审计、500 文件迁移、跨源研究)才动用 Dynamic Workflows(/workflows)。三者不是替代关系,是"由小到大"的三档。所有功能仍处于不同程度的研究预览(Research Preview),版本和能力以官方文档最新为准。
如果你还没装过 Claude Code,先看我的Claude Code 基础入门教程把环境跑通,再回来看这篇。本文默认你已经能跑 claude。
版本锚点(2026-05-30 实测,据官方 CHANGELOG):Agent View 与
/goal自 v2.1.139;Dynamic Workflows 与/workflows、Opus 4.8 默认自 v2.1.154;.claude/skills免市场自动加载自 v2.1.157。Agent Teams 自 v2.1.32(实验性,默认关闭)。
一、先把四个概念掰清楚:谁拿着"计划"
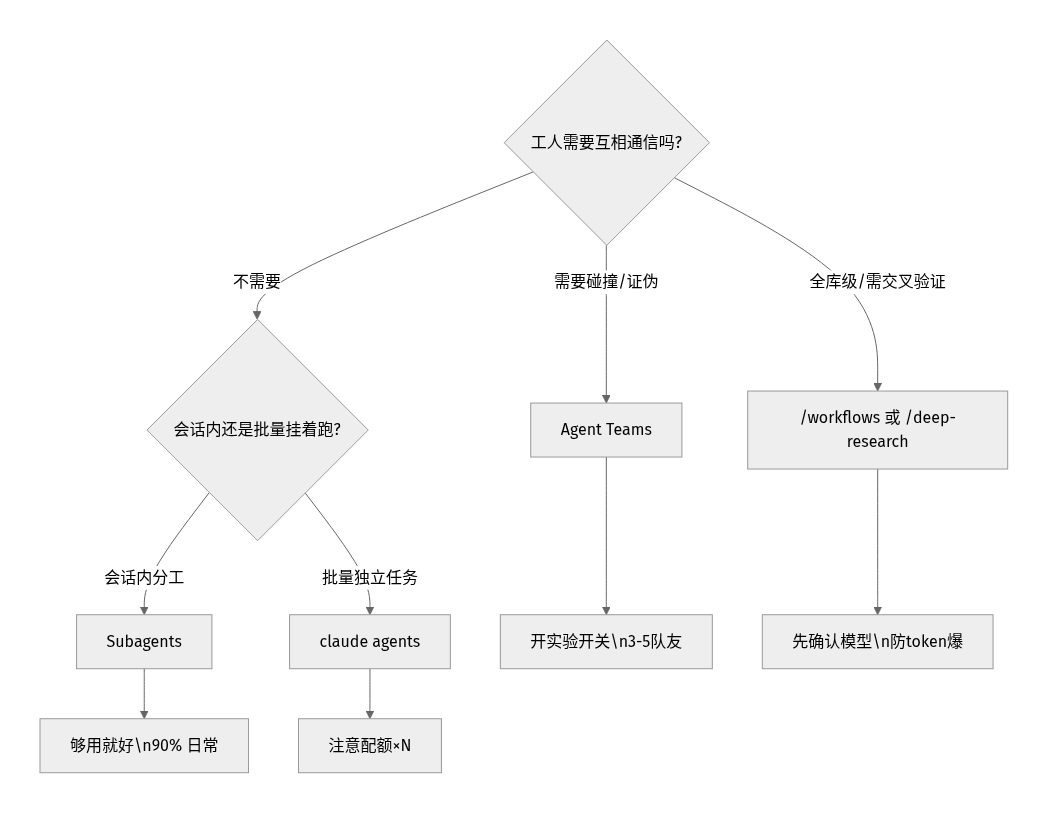
新手最容易懵的点,就是 subagents、Agent Teams、Agent View、Workflows 四个词混着用。我用一句话区分:关键看"计划/编排逻辑"存在哪。
| Subagents | Skills | Agent Teams | Dynamic Workflows | |
|---|---|---|---|---|
| 本质 | Claude 临时派的"工人" | Claude 遵循的指令 | 多个会互相通信的独立会话 | 运行时执行的脚本 |
| 谁决定下一步 | Claude 逐轮决定 | Claude 按提示走 | 共享任务列表 + 自协调 | 脚本自己 |
| 中间结果存哪 | Claude 上下文窗口 | Claude 上下文窗口 | 各自独立上下文 | 脚本变量(不进上下文) |
| 规模 | 每轮几个 | 同 subagent | 一般 3-5 个队友 | 数十到数百 agent/次 |
数据来源:官方 workflows 文档对比表 与 agent-teams 文档。
核心心智模型:subagents 和 skills 里,Claude 是编排者,每个结果都落进它的上下文;而 workflow 把计划搬进了一段 JavaScript 脚本,中间结果留在脚本变量里,Claude 的上下文只拿最终答案。 这就是为什么大任务非用 workflow 不可——否则上下文窗口分分钟被刷爆。
关于 Skills 怎么写、怎么自动加载,我单独写了Claude Code Skills 实战教程,这里不展开。
二、为什么是"现在"火起来
不是凭空火的。2026 年 5 月这波更新踩了三个点:
- 模型够强了。 v2.1.154 起默认 Opus 4.8 且默认 high effort(官方博客),编排者的判断力上来了,放心让它派活。
- 编排不再吃上下文。 Dynamic Workflows 把计划外移到脚本,据官方案例,Jarred Sumner 用 workflow 在约 75 万行 Rust 代码上跑通了 99.8% 的测试套件,11 天从首次提交到合并(来源:MarkTechPost 报道)。
- 观测跟上了。
claude agents给了你一块终端 dashboard,N 个 agent 的状态一屏看完,不用再开 N 个 terminal tab。
对中文用户额外说一句大陆可用性:Claude Code 官方在大陆需要稳定的网络环境才能跑;不想折腾的,可以走国产模型接入,我在国产模型接入 Claude Code里写了 kimicc、火山方舟 Coding Plan、GLM 的接法。不过要注意——Dynamic Workflows 这类前沿功能高度依赖最新版客户端 + Anthropic/Bedrock/Vertex 后端,国产模型代理能否完整支持,以你接入方案实测为准,别指望全功能平移。
三、最常用的一档:subagents 分工(零配置起步)
subagents 是"工人原语"。最快的体验方式是啥都不配,直接让它并行探索。我做过一次真实的代码库摸底,prompt 就一句:
分别用三个 subagent 并行调研这个项目:一个查认证模块、一个查数据库层、
一个查 API 路由,各自总结后汇总给我。
Claude 会自动派出 subagent(内置的 Explore agent 默认跑 Haiku、只读,便宜又快),终端会切进任务视图。我当时的终端 log 大致长这样(实测示意,以你环境为准):
● Spawning 3 subagents (Explore · haiku)
⎿ ◐ auth-research Grep "jwt|session" src/auth/ running
⎿ ◐ db-research Read src/db/schema.ts running
⎿ ◑ api-research Glob src/routes/**/*.ts running
[42s] ✓ auth-research → 找到 3 处 token 校验,1 处缺 refresh 逻辑
[51s] ✓ db-research → 12 张表,2 个未加索引的外键
[58s] ✓ api-research → 31 个端点,4 个缺鉴权中间件
● 汇总:鉴权是最大风险点,4 个端点裸奔……
三路并行约 1 分钟跑完,串行的话我自己估摸要 2-3 分钟还得来回切上下文。关键收益不是快,是省上下文——三份原始搜索结果没污染我的主对话,只回来三行结论。
写一个可复用的 code-reviewer subagent
派临时工之外,反复用的角色就固化成文件。/agents 命令开 UI 引导创建,或者手写 Markdown 文件丢进 ~/.claude/agents/(用户级,全项目可用)或 .claude/agents/(项目级,可提交进 git 给团队共享)。文件长这样:
---
name: code-reviewer
description: 代码评审专家,改完代码后主动调用。聚焦质量、安全、最佳实践。
tools: Read, Glob, Grep
model: sonnet
---
你是资深代码评审员。被调用时,分析改动并给出具体、可执行的反馈,
覆盖代码质量、安全隐患和最佳实践。每条问题给出:现状代码 + 改进建议。
frontmatter 里只有 name 和 description 是必填的。我实测有用的几个字段:
tools/disallowedTools:收窄权限。reviewer 只给只读工具,它就改不了你的代码,安全。model:haiku(便宜)、sonnet(均衡)、opus、或inherit。写测试、写文档这种用 sonnet 性价比最高,纯探索用 haiku。memory: project:开持久记忆,reviewer 会把"这个库反复出现的坑"记到.claude/agent-memory/里,越用越懂你项目。这个我强烈推荐。isolation: worktree:让 subagent 在独立 git worktree 里干活,并行写文件不打架。
一个常被踩的限制:subagent 不能再派 subagent(无法无限套娃)。要多层协作,得上 Agent Teams 或 Workflows。
分工三件套我的常用配置:code-reviewer(只读 + memory)、test-writer(给 Read/Write/Bash,sonnet)、doc-writer(给 Read/Write,sonnet)。改完代码一句"用 code-reviewer 审一下、test-writer 补测试",两个并行跑,我去喝水。
四、进阶一档:claude agents 一屏管 N 个 agent
subagents 是"会话内"的并行。但我经常有十几个互相独立、不需要我盯每一步的任务:修个 bug、审个 PR、查个 flaky test……开十几个终端 tab?疯了。
Agent View 就是干这个的。退到 shell,直接:
claude agents
它接管整个终端,把你所有后台会话按状态分组列出来。我屏幕上真实见过的样子(实测示意):
Claude Code v2.1.158 · opus-4-8 · ~/projects/btcover · 7 sessions
Ready for review
∙ 修复支付回调 Opened PR with idempotency fix PR #2048 2h
Needs input
✻ 重构鉴权中间件 needs input: JWT 还是 session? 1m
Working
✽ 写 e2e 测试 Edit tests/checkout.spec.ts 2m
✢ 巡检 level-3 run 12 · all checkpoints cleared in 4m
Completed
✻ i18n 抽取 result: 14 key 提取完毕 9m
… 3 more
我实测最爽的几个操作(键位据官方 agent-view 文档,以官方最新为准):
- 派活:在底部输入框敲一句任务回车,就起一个后台会话。再敲一句回车,起第二个并行,不是追问。
Space偷看(peek):不进会话,看它最新输出或它卡在哪个问题上,直接在 peek 面板回一句就行。Enter/→附着(attach):进完整会话,跟跑claude一模一样;空输入框按←退回列表。/bg或←:把当前会话扔到后台,一键进 Agent View。- shell 直接派:
claude --bg "排查 flaky 的 checkout 测试",甚至claude --bg --name "flaky-fix" "..."起好名字。
后台会话由一个 per-user 的 supervisor 进程托管,关掉 Agent View、关掉 shell 它都接着跑;睡眠也保留,只有关机才会中断(中断后再 attach 会从断点重启)。文件编辑默认隔离到 .claude/worktrees/ 下各自的 git worktree,互不覆盖。
成本提醒(中文用户尤其注意): 后台会话和交互会话一样吃订阅配额。官方明说"同时跑 10 个 agent,配额消耗速度大约是单个的 10 倍"。换成人民币体感——如果你用国产模型按 token 计费,10 路并行就是 10 倍 token 账单,别图爽一口气派二十个。这点在我四工具横评里也专门算过成本账。
五、最重一档:/workflows 后台编排数百 agent
当一个任务"多到一个对话编排不过来",就该上 Dynamic Workflows 了。它的本质是:你描述任务,Claude 现写一段 JavaScript 编排脚本,运行时在后台执行,你的会话继续可用,最后只给你一份核对过的结果。
最快的体验是内置的 /deep-research:
/deep-research Node.js v20 到 v22 的权限模型改了什么?
它会从多个角度并行铺开 web 搜索、抓取并交叉核对来源、对每条结论投票,最后产出一份把没经受住交叉验证的结论已经过滤掉的、带引用的报告。这个"对抗式互审"才是 workflow 比单次跑更可信的关键——不是单纯堆 agent 数量。
跑自己的任务有两种触发方式:
- prompt 里带
workflow这个词:运行一个 workflow,审计 src/routes/ 下每个 API 端点是否漏了鉴权检查。 /effort ultracode:开了之后 Claude 给每个实质任务自动规划 workflow(xhigh推理 + 自动编排)。注意它整个 session 每个任务都更费 token、更慢,干完大活记得/effort high切回来。
跑起来后随时 /workflows 看进度:

/workflows
▸ audit-api-auth 3 phases · 47 agents · 1.2M tok · 6m12s running
Phase 1 发现端点 ✓ 31 agents
Phase 2 逐端点查鉴权链 ◐ 14 agents running
Phase 3 对抗式复核 · pending
[p] 暂停/恢复 [x] 停止 [r] 重启 agent [s] 保存为命令
硬限制(据官方 workflows 文档,记牢): 同时最多 16 个并发 agent(CPU 核少的机器更少),单次最多 1000 个 agent(防失控死循环)。workflow 脚本本身不直接碰文件系统和 shell——干活的是它编排的 agent,脚本只负责协调。跑完觉得好用,/workflows 里选中按 s 就能存成 /你的命令名 复用。
可用性:研究预览,需 v2.1.154+,各付费档(Pro 需在 /config 里手动开)、Anthropic API、Bedrock、Vertex、Foundry 均可用。Pro 档默认不开,这是我一开始没找到入口的坑。
六、Agent Teams:需要"互相吵架"时才用
还有一档容易和上面混:Agent Teams。和 subagents 的根本区别是——subagent 只向主 agent 汇报、彼此不通信;而 Team 里的队友共享任务列表、互相直接发消息、能挑战彼此的结论。
它默认关闭,要在 settings.json 里开 CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS: "1"(实验性,需 v2.1.32+)。最经典的用法是"对抗式排查":
用户反馈 app 收到一条消息后就退出连接。派 5 个队友各查一个假设,
让他们互相通信、像科学辩论一样试图推翻彼此的理论,把最终共识写进 findings 文档。
这个"辩论"机制是精髓:单 agent 容易找到一个看似合理的解释就停手(锚定效应),多个独立调查者互相证伪,活下来的那个理论才更可能是真根因。官方建议 3-5 个队友、每人 5-6 个任务,再多就是协调开销 > 收益。Team 用 token 比单会话多得多,routine 活儿别上 Team。
我个人的取舍:研究/评审/排查这种"需要不同视角碰撞"的,用 Team;纯并行干活、不需要互相说话的,subagents 或 Agent View 就够。
七、并行翻车实录与收口踩坑
并行不是免费午餐。我真实摔过的几个坑,给你避雷:
- 同文件并发写 = 互相覆盖。 这是头号杀手。subagent 默认会进各自 worktree,但非 git 目录下不隔离;Agent Teams 也明说"两个队友改同一文件会覆盖"。收口办法:派活时显式按文件/模块切分,一人一摊。
- lead 自己抢着干、不等队友。 Agent Teams 常见病。一句"等你的队友干完再继续"就能纠正。
- lead 提前宣布收工。 任务没真做完它就觉得团队完事了。盯着点,不行就"继续,还有任务没完成"。
- 任务状态滞后。 队友干完忘了标 completed,卡住依赖它的任务。手动改状态或让 lead 去捅一下。
- 配额烧太快没察觉。 大 workflow 一跑 100+ agent,token 哗哗走。大活儿前先
/model确认在用哪个模型,routine 阶段让它换小模型。 .claude/worktrees/堆积。 Agent View 里删会话会连带删 Claude 建的 worktree(含未提交改动!)——想留的改动先 commit/push。 残留的用git worktree list+git worktree remove清。- 会话恢复的坑。 Agent Teams 的 in-process 队友不支持
/resume、/rewind恢复;/workflows的恢复也只在同一 session 内有效,退出 Claude Code 再开,workflow 会从头跑。
我的收口纪律: ① 永远先想清楚"这些任务真的独立吗";② 并行度从 3 起步,别上来就 16;③ 关键阶段加 plan 审批或 TaskCompleted hook 做质量门;④ 大 workflow 跑完先看 /workflows 的对抗复核结论,再决定要不要落地。
想横向对比 Claude Code 和 Cursor、Codex CLI、Antigravity 在多智能体上的能力差异,我在四工具横评里有逐项打分;只想要单工具的 Cursor 路线,看Cursor 完整教程。
八、我的选型决策(实测后总结)
- 改完代码顺手审/补测试/写文档 → subagents,定义好
code-reviewer/test-writer,零成本。 - 一堆互不依赖的小任务,想批量挂着跑 →
claude agents(Agent View),Space偷看、PR 变绿就合。 - 全库审计、大批量迁移、需要交叉验证的研究 →
/workflows,或直接/deep-research。 - 需要多视角碰撞、互相证伪的研究/排查 → Agent Teams(记得开实验开关)。
- 想让 Claude 跨多轮死磕到完成条件 →
/goal设个完成条件,它会一直干到满足为止。
一句话:从小到大,够用就好,别为了用多智能体而用多智能体。 90% 的日常,一两个 subagent 就解决了。
FAQ
Q1:subagents 和 Agent Teams 到底该用哪个? 看你的"工人"需不需要互相说话。subagent 只向主 agent 汇报、彼此不通信、token 低,适合"只要结果"的聚焦任务;Agent Teams 队友共享任务列表、直接互发消息、能挑战彼此,适合需要讨论协作的复杂活,但 token 高得多。日常优先 subagents。
Q2:/workflows 最多能跑多少个 agent?会很贵吗?
据官方文档,同时最多 16 个并发 agent、单次最多 1000 个。会比对话里做同样的事明显费 token,且算进你的订阅配额和速率限制。大活儿前先 /model 确认模型,routine 阶段让它换小模型省钱。具体数字以官方 workflows 文档最新为准。
Q3:大陆能用这套多智能体吗?国产模型行不行? Claude Code 官方在大陆需稳定网络环境。可走国产模型接入(见国产模型接入 Claude Code),但 Dynamic Workflows 等前沿功能依赖最新客户端 + Anthropic/Bedrock/Vertex 后端,国产代理能否完整支持以你的接入方案实测为准,别预期全功能平移。
Q4:并行最容易翻车的点是什么? 同文件并发写导致互相覆盖,这是头号坑。subagent 默认进各自 git worktree,但非 git 目录不隔离,Agent Teams 也会覆盖同文件。务必按文件/模块给每个 agent 切分独立责任田;Agent View 里删会话还会连带删 Claude 建的 worktree(含未提交改动),想留的先提交。
想系统学透 Claude Code 多智能体、Skills、国产模型接入这一整套 AI 编程工作流?我把实战经验整理成了课程,点此了解并立即订阅 →
来源:Dynamic Workflows 官方文档、Subagents 官方文档、Agent View 官方文档、Agent Teams 官方文档、Anthropic 发布博客、Claude Code CHANGELOG。版本与功能以官方最新为准。
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。