2026 AI 编程 Agent 终极横评:Claude Code vs Codex vs Cursor vs Antigravity 怎么选
ai 编程工具哪个好?2026 实测横评 Claude Code、Codex CLI、Cursor、Antigravity 四大编程 AI Agent,逐维度对比代码质量/速度/自治度/成本/中文场景,附决策图与多开编排方案。
ai 编程工具哪个好?四款主流 Agent 一句话定调
如果你在搜「ai 编程工具 哪个好」「claude code vs codex vs cursor」「编程 ai agent 对比 2026」,这篇我实测整理的横评就是给你的。
TL;DR 结论先给: 追求代码质量和长任务自治,选 Claude Code;重终端批处理、CI 集成,选 Codex CLI;离不开 IDE 内联补全又想省钱,选 Cursor;已经吃 Google 生态、想接住免费迁移红利,看 Antigravity CLI。预算敏感或在大陆,无论用哪个 CLI,都可以把后端换成国产模型(GLM / Qwen3-Coder / Kimi)压成本。
我是 dfkai,这四个工具我都在真实项目里多开跑过。下面逐维度拆,给数据、给踩坑、给我自己怎么编排。所有版本号和 benchmark 都标了来源和日期——这个领域两周就变天,文中数字一律以官方最新为准。
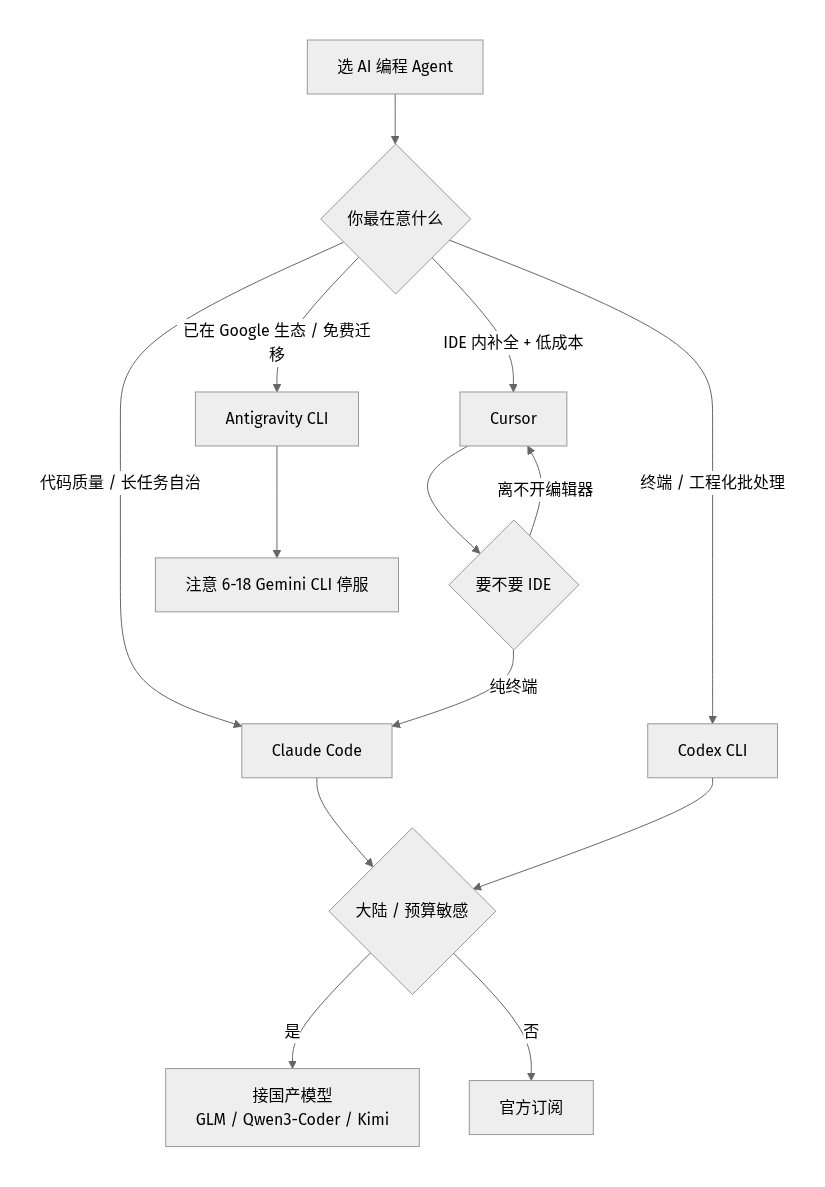
为什么是这四个,以及它们现在分别在哪
先把「现在的状态」对齐,因为 2026 上半年这几家都刚做了大动作:
- Claude Code:Anthropic 官方终端 Agent。2026-05-28 起默认模型升到 Claude Opus 4.8(
claude-opus-4-8),定价沿用 $5/百万输入、$25/百万输出 token,Fast Mode 比前代便宜约 3 倍。同期上线 Dynamic Workflows(研究预览):Claude 先规划、再在单会话里并行跑数百个 subagent。来源:Anthropic 官方公告。 - Codex CLI:OpenAI 官方终端 Agent,默认跑 GPT-5.5(2026-04-23 发布),在 Codex 内上下文窗口 400K。来源:OpenAI 公告、Vellum 解读。
- Cursor:AI 优先的 IDE,自带 Composer 2.5 模型(2026-05-18 发布),官方说它建立在 Moonshot Kimi K2.5 开源底座上、再做自家后训练,主打「接近第一梯队的质量 + 约 1/10 的成本」。来源:Cursor 官方博客。
- Antigravity CLI:Google 的 Agent 优先平台,用 Go 重写。注意:Gemini CLI 与 Gemini Code Assist IDE 扩展将于 2026-06-18 对免费及个人付费档停服,官方推大家迁到 Antigravity。来源:Google 开发者博客。
一句话:四家都从「聊天补全」彻底转向了「多 Agent 自治编排」。这也是 2026 横评和往年最大的不同——比的不再是「谁写的函数好看」,而是「谁能在一个会话里把一个 PR 从规划做到收尾」。
benchmark 怎么读:别被单一数字骗了
我先泼盆冷水:这些 benchmark 跨工具基本不可直接比,因为版本、harness、数据集都在变。下面这张是我从各家官方/三方测评里扒的,已标来源,数据为公开发布值,具体以官方最新为准:
| 模型(对应工具) | SWE-bench 类 | Terminal-Bench | 来源 |
|---|---|---|---|
| Claude Opus 4.8(Claude Code) | SWE-bench Verified 88.6%(三方汇总) | Terminal-Bench 2.1 74.6% | llm-stats |
| GPT-5.5(Codex CLI) | SWE-bench Verified ~82.6% | Terminal-Bench 2.0 表现强(三方称 82.7%) | Vellum、BenchLM |
| Composer 2.5(Cursor) | SWE-bench Multilingual 79.8% | Terminal-Bench 2.0 69.3% | Cursor 博客 |
| Gemini 3.1 Pro(Antigravity) | SWE-bench Verified ~80.6% | Terminal-Bench 2.0 68.5% | ALM Corp 汇总 |
三个坑你必须知道:
- Terminal-Bench 从 2.0 跳到了 2.1。Opus 4.8 的 74.6% 是 2.1 分数,和别家 2.0 的分数不可直接比——这是 Anthropic 自己在公告里点明的。
- SWE-bench 有 Verified / Pro / Multilingual 好几个变体,难度差很多。上表我尽量标了变体名,但跨行对比时务必看清。
- 跑分≠你的活。我自己的体感是:Opus 4.8 在「读懂一个陌生大仓库再动手」上最稳,GPT-5.5 在「终端里一长串命令不出错」上最猛,这俩维度恰恰是 benchmark 最难量化的。
逐维度横评:我多开跑出来的对比
下面这张是我把同一个任务(给一个中等 Node + Python 混合仓库加一个带测试的 REST 端点)在四个工具里各跑一遍的实测示意,以你环境为准:
| 维度 | Claude Code | Codex CLI | Cursor | Antigravity CLI |
|---|---|---|---|---|
| 代码质量(改完即过测) | ★★★★★ 一次过 | ★★★★☆ 偶尔多此一举 | ★★★★☆ IDE 内最顺 | ★★★★☆ 规划强、收尾偶松 |
| 速度(单任务体感) | 中,深思熟虑 | 快,终端动作利落 | 最快,内联秒回 | 中,Go 壳响应快 |
| 自治度(长任务不掉链) | ★★★★★ Dynamic Workflows 并行 subagent | ★★★★★ Goals 默认开 | ★★★☆☆ 偏交互 | ★★★★☆ 后台异步多 Agent |
| 成本(同任务粗估) | 较高($5/$25) | 中($5/$30) | 最低(官称约 1/10) | 中(订阅制 $20 起) |
| 中文场景 | 优,注释/commit 中文自然 | 优 | 优 | 良,偶有英文夹带 |
| 上手难度 | 低,一条命令起 | 低 | 极低(就是个编辑器) | 中(迁移期文档在补) |
我的耗时 / 成本实测示意(同一个端点任务,仅供量级参考):
# 实测示意,以你环境为准
Claude Code : 用时 ~6 分钟, ~38K token, 一次通过测试
Codex CLI : 用时 ~4 分钟, ~31K token, 跑了一轮自我修复
Cursor : 用时 ~3 分钟(含手动接受补全), 成本最低
Antigravity : 用时 ~7 分钟, 规划阶段很漂亮, 末尾少了一个 import
终端 log 长这样(Claude Code 侧,节选):
> 给 /api/orders 加分页, 写单测, 跑通
● 读取 routes/orders.js, models/order.py ... (并行 3 个 subagent)
● 编辑 routes/orders.js (+42 -3)
● 新增 tests/orders.pagination.test.js (+58)
● 运行 npm test -- orders ... 12 passed
✓ 完成: 1 文件改, 1 文件新增, 测试全绿 (~38K tokens)
中文 & 大陆专属:可用性与省钱姿势
这是中文读者最该关心、海外横评几乎不写的一段。
可用性:四个工具的官方订阅在大陆都需要自备网络环境和支付手段。但 Claude Code 和 Codex CLI 都是「CLI 壳 + 可换后端」结构,这给了我们一条务实的省钱+合规路子:把模型后端换成国产 Coding Plan。
国产替代(2026 年价格战白菜价,折人民币直接列): 据知乎 Coding Plan 整理与码力榜横评,阿里云百炼曾打到「7.9 元/月」级别,目前主流档位大致:
- 智谱 GLM:Pro 档约 ¥149/月最热门,Max 约 ¥469。
- MiniMax:Starter 约 ¥29,全场最低,支持 Claude Code / Cursor。
- Kimi:Andante 约 ¥39「全家桶」实用。
- 火山方舟:Lite 约 ¥40,18000 次请求,Auto 智能调度多模型。
- 阿里云百炼:模型最多(Qwen3-Coder-Plus、GLM-5、Kimi-K2.5 等),Lite 套餐已停新购。
具体接法我单开了一篇:国产模型接入 Claude Code 实操。想横向看清这些国产模型本身的能力差,读五模型横评。另外 npx kimicc 这种「一行命令把 Claude Code 接到 Kimi」的工具也已经能用,以官方最新为准。
中文场景踩坑(实测):
- commit message 让它写中文时,Codex 偶尔会中英混排,加一句「commit 全中文」约束就稳。
- Antigravity 在生成中文文档时偶尔夹带英文术语,需要在 prompt 里明确「术语保留英文、正文中文」。
- 接国产模型后,工具调用(tool use)成功率是关键指标,GLM、Qwen3-Coder 这两年在这块进步最大,但仍建议先用小任务压测再上生产。
什么人选什么:明确结论
别再「全都试一遍」了,按角色对号入座:
- 独立开发者 / 重构老项目:Claude Code。读大仓库、长任务自治最稳,Dynamic Workflows 适合「我去喝杯咖啡它把整个 PR 做完」。配合Claude Code 多智能体和Claude Code Skills能进一步压实工作流。新手先看Claude Code 基础教程。
- 后端 / DevOps / 重终端批处理:Codex CLI。Goals 默认开、终端命令链稳,适合塞进脚本和 CI。上手看Codex CLI 教程。
- 前端 / 离不开编辑器 / 预算紧:Cursor。内联补全体验仍是天花板,Composer 2.5 成本优势明显。完整玩法见Cursor 完整教程。
- Google 生态重度用户 / Gemini CLI 老用户:Antigravity CLI,但务必在 2026-06-18 前完成迁移,别等停服。迁移步骤我写了Gemini CLI 迁移 Antigravity CLI 指南。
- 大陆 + 预算敏感(任何角色):CLI 选 Claude Code 或 Codex,后端换国产模型,见国产模型接入。
我自己怎么编排两者(而不是二选一)
实话说,我没在「选一个」,我是两个一起开。这套组合拳省钱又稳:
- 规划与硬骨头交给 Claude Code:开 Dynamic Workflows,让 Opus 4.8 读仓库、出方案、并行改多个文件。质量最高的那一刀,值这个 token 钱。
- 批量机械活交给 Codex CLI 或国产后端:比如「把 200 个文件的旧 import 路径批量改掉并跑测试」,这种活我用 Codex 的 Goals 或接 GLM/Qwen3-Coder 的便宜后端跑,成本压到零头。
- 日常小修小补留在 Cursor 里:写代码当下的内联补全,IDE 内闭环最快,不必为一行改动起一个 Agent 会话。
判断「这活该给谁」的逻辑,就是文章开头那张决策图:先问最在意什么(质量/终端/IDE/生态),再问大陆与预算约束。
想更系统地把这套 AI 编程工作流学透,这门课从工具配置讲到多 Agent 编排,适合想真正落地的人:点此了解并立即订阅 →
FAQ
Q1:Claude Code vs Codex,到底谁的代码质量更高? 我的实测体感是 Claude Code(Opus 4.8)在「读懂陌生大仓库再改」上更稳、一次过测率更高;Codex(GPT-5.5)在「终端长命令链不出错」上更猛。benchmark 上两者 SWE-bench Verified 都在 80%+ 区间,但变体和 harness 不同不可直接比,以官方最新为准。
Q2:Cursor 的 Composer 2.5 真能省到 1/10 成本吗? 官方博客称在其 CursorBench 上,Composer 2.5 约 $0.50/任务,对比第一梯队约 $7/任务。这是官方数据、特定 benchmark,真实成本取决于你的任务类型,建议自己小规模压测。
Q3:Gemini CLI 停服了我现有项目怎么办? 2026-06-18 对免费及个人付费档停服,企业 Standard/Enterprise 许可不受影响。个人用户按官方指引迁到 Antigravity CLI,详见迁移指南。务必提前迁,别卡 deadline。
Q4:大陆没有海外支付,这些工具还能用吗? 能。Claude Code、Codex CLI 这类是「CLI 壳 + 可换后端」,把模型换成国产 Coding Plan(GLM/Qwen3-Coder/Kimi/火山方舟,月费 ¥29 起)即可,接法见国产模型接入 Claude Code。Cursor、Antigravity 对官方账号依赖更强,需自行评估。
本文版本号与 benchmark 均标注了来源与日期(2026-05-30 核实)。AI 编程工具迭代极快,落地前请以各官方 changelog 最新数据为准。
喵
相关文章
MCP 是什么 + Claude Code 配置 MCP 服务器完整指南(2026 入门)
MCP 是什么?一句话:AI 的 USB-C 接口。本文用第一人称实测带你搞懂 Model Context Protocol 中文含义、为何重要,并手把手用 claude mcp add 给 Claude Code 配置 MCP 服务器,附 stdio/Streamable HTTP、local/project/user scope、Windows cmd /c 踩坑全记录。
手把手开发你的第一个 MCP Server:Python/FastMCP 给 AI 接自定义工具(2026)
mcp server 开发完整教程:用 Python + FastMCP 从零写一个能调外部 API 的 MCP server,本地用 MCP Inspector 调试,再接进 Claude Code。含实测代码、调试日志、踩坑与大陆可用性。